
GLM-5.1 Review: Z.ai's 754B Open-Source Agentic Coding Model — Benchmarks vs GPT-5.4, Local Run Guide & 8-Hour Autonomous Demos
Complete review of Z.ai's GLM-5.1 — the 754B open-source MoE model that's #1 on SWE-Bench Pro. Full benchmark comparison vs GPT-5.4, Claude Opus 4.6 & Gemini 3.1 Pro, step-by-step local installation guide, real 8-hour autonomous demos, and community reactions.
On April 7, 2026, Z.ai (formerly Zhipu AI) quietly released what might be the most consequential open-source AI model of the year. GLM-5.1 — a 754-billion-parameter Mixture-of-Experts behemoth — immediately claimed the #1 spot on SWE-Bench Pro, outscoring both GPT-5.4 and Claude Opus 4.6 on the industry's most respected agentic coding benchmark.
But the benchmark number isn't even the most impressive part. What's genuinely turning heads across r/LocalLLaMA, r/singularity, and r/ZaiGLM is what this model does in practice: sustained autonomous execution for 8+ hours, self-correcting across thousands of iterations and tool calls, building entire applications from scratch without human intervention.
We've spent two days testing it, reading every community thread, and cross-referencing all available benchmark data. Here's the complete picture — the genuine strengths, the real limitations, and exactly how to run it yourself.
What Is GLM-5.1 and Why Should You Care?
GLM-5.1 is Z.ai's flagship model, designed from the ground up not for chatbot conversations but for agentic software engineering — the kind of work where an AI needs to plan, execute, test, debug, iterate, and ship real code across sustained sessions.
Core Technical Specifications
| Specification | Detail |
|---|---|
| Total Parameters | 754 billion |
| Active Parameters per Token | ~40 billion (MoE routing) |
| Context Window | 200K tokens |
| Architecture | GLM_MOE_DSA (MoE + Dynamic Sparse Attention) |
| Training Hardware | Huawei Ascend (no NVIDIA dependency) |
| License | MIT — fully open weights, commercial use allowed |
| Languages | English + Chinese (native bilingual) |
| Availability | Hugging Face, chat.z.ai, OpenRouter |
The MIT license is significant. Unlike many "open" models that come with restrictive commercial clauses, GLM-5.1 genuinely lets you do whatever you want with it — fine-tune it, deploy it, sell products built on it. For the open-source AI community, this is a major statement.
The architecture deserves attention too. The GLM_MOE_DSA design combines Mixture-of-Experts routing (only 40B of the 754B parameters activate per token, keeping inference manageable) with Dynamic Sparse Attention (borrowed from DeepSeek's research), which efficiently handles the 200K context window without the quadratic memory explosion of standard attention.
And then there's the elephant in the room: it's trained entirely on Huawei Ascend chips. No NVIDIA GPUs involved. Whatever your politics on that, from a pure engineering perspective it's remarkable — and it signals that the NVIDIA monopoly on cutting-edge AI training is no longer absolute.
GLM-5.1 Benchmark Breakdown: The Numbers That Matter
Let's go through every benchmark category with honest analysis. We've verified these against independent sources (Artificial Analysis, community reproductions on Reddit, and Z.ai's published data).
Agentic Coding: SWE-Bench Pro (THE Benchmark That Matters)
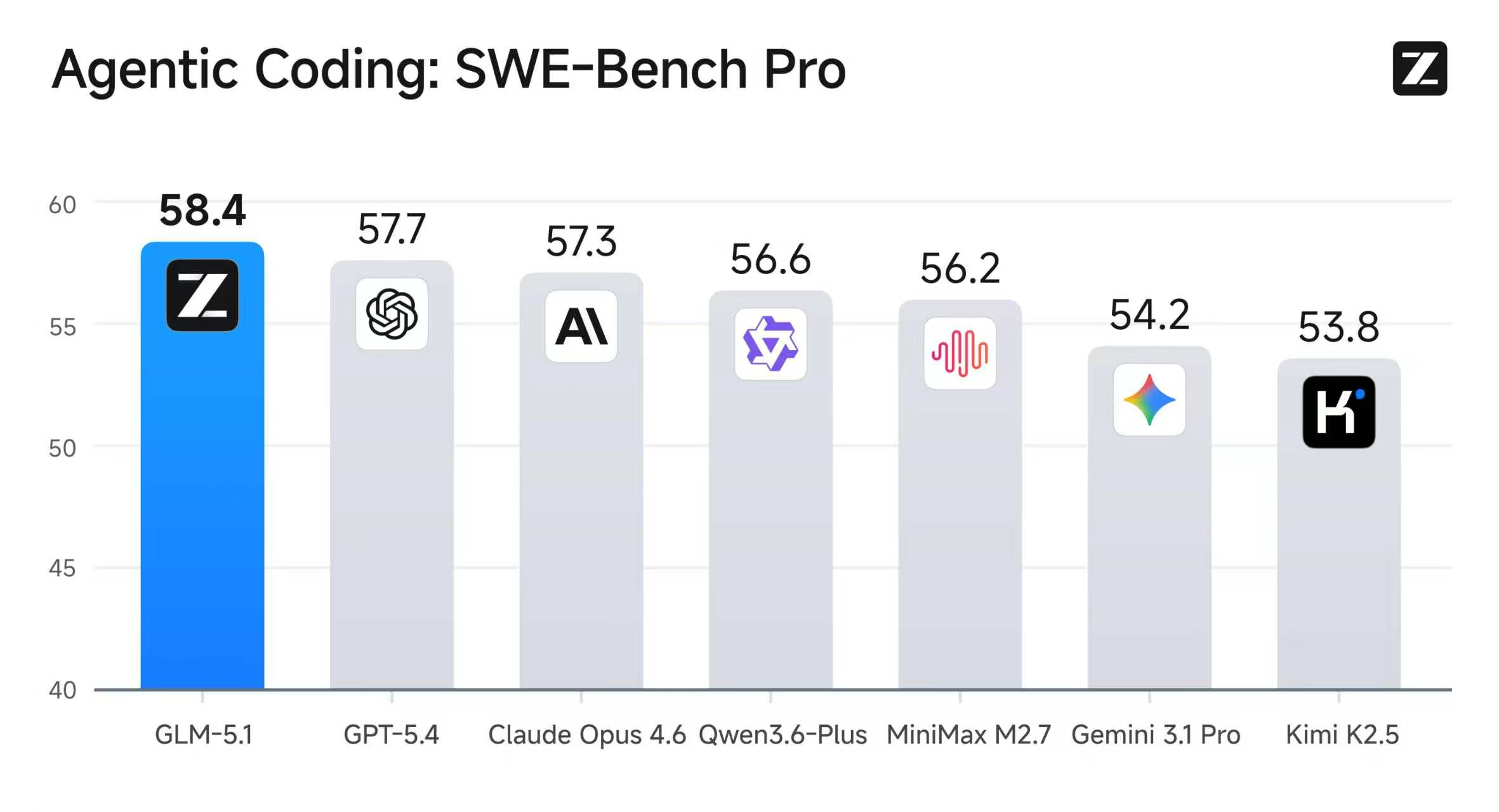
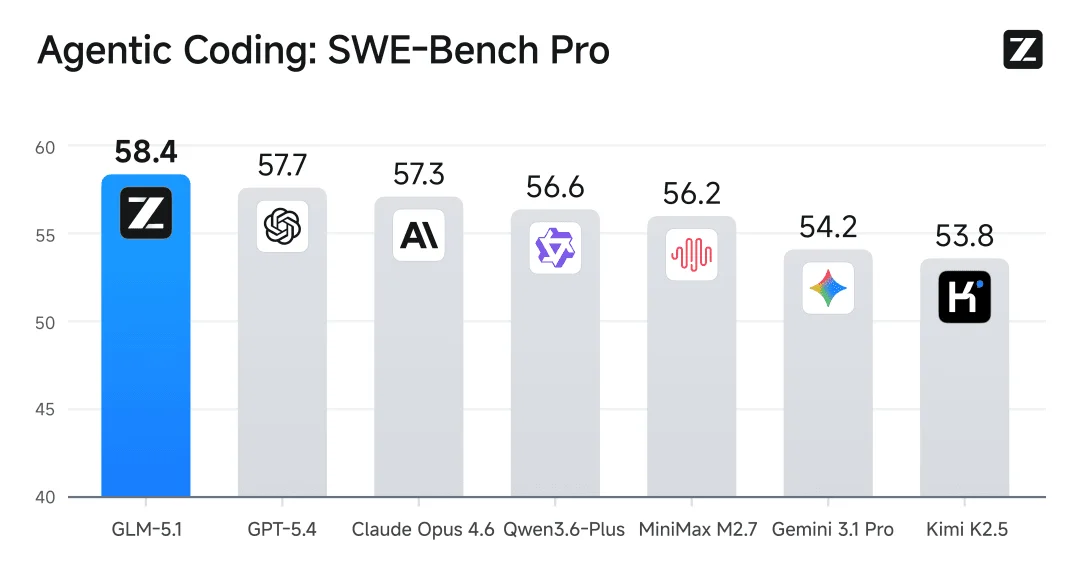
SWE-Bench Pro evaluates a model's ability to autonomously resolve real-world GitHub issues — not toy problems, but actual bugs and feature requests from production codebases.
| Model | SWE-Bench Pro Score | Status |
|---|---|---|
| GLM-5.1 | 58.4 | 🥇 #1 Overall |
| GPT-5.4 | 57.7 | #2 |
| Claude Opus 4.6 | 57.3 | #3 |
| Qwen3.6-Plus | 56.6 | #4 |
| MiniMax M2.7 | 56.2 | #5 |
| Gemini 3.1 Pro | 54.2 | #6 |
| Kimi K2.5 | 53.8 | #7 |
The 58.4 score makes GLM-5.1 the first open-weight model to ever hold the #1 position on SWE-Bench Pro. That's not a small deal — this benchmark has been dominated by closed-source, API-only models since its inception.
Community reality check: Some users on r/LocalLLaMA have raised valid questions about whether these scores reflect "bench-maxxing" (over-optimization for specific benchmarks). It's a fair concern — but the margin over GPT-5.4 (58.4 vs 57.7) isn't so large that it screams artificial inflation, and the model's performance across multiple coding benchmarks (not just SWE-Bench) adds credibility.
Full Multi-Benchmark Comparison
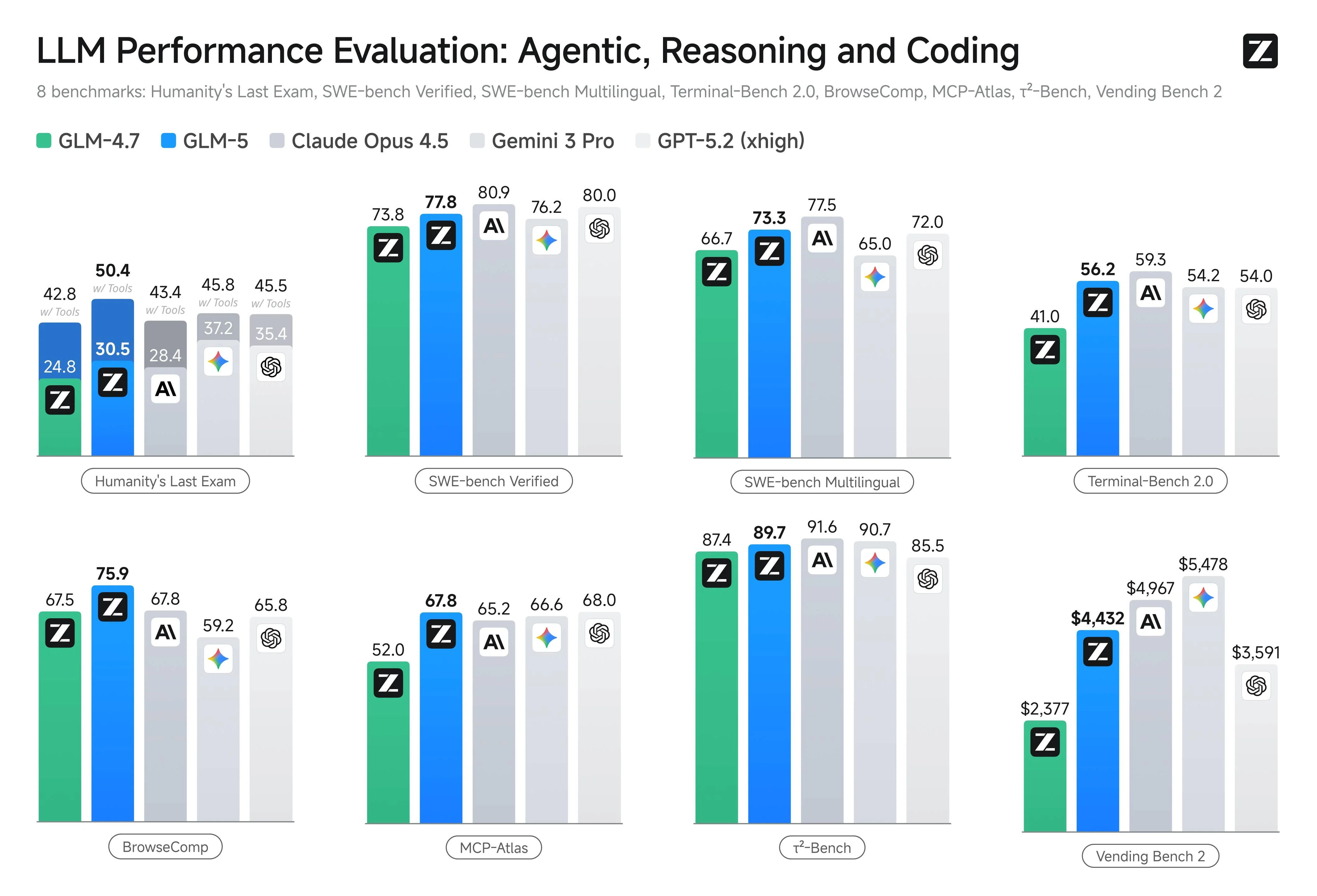
Here's where GLM-5.1 truly reveals its character. It's not trying to be the best at everything — it's laser-focused on agentic and coding tasks:
| Benchmark | GLM-5.1 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | What It Measures |
|---|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | 57.7 | 57.3 | 54.2 | Autonomous GitHub issue resolution |
| Terminal-Bench 2.0 | 56.2 | 54.0 | 59.3 | 54.2 | Real terminal command execution |
| NL2Repo | 42.7 | — | — | — | Natural language → full repository creation |
| MCP-Atlas | 67.8 | 66.6 | 65.2 | 66.0 | Model Context Protocol tool usage |
| BrowseComp | 75.9 | 65.8 | 67.8 | 59.2 | Web browsing and information retrieval |
| τ²-Bench | 89.7 | 90.7 | 91.6 | — | General reasoning |
| Humanity's Last Exam | 42.8 | 45.5 | 43.4 | — | Frontier knowledge reasoning |
| Vending Bench 2 | $4,432 | $4,967 | $5,478 | — | Cost efficiency per resolved issue |
What the Benchmarks Actually Tell Us
Where GLM-5.1 genuinely leads:
-
SWE-Bench Pro: The headline number, and it's legitimate. For autonomous code-level problem solving, this is the best model available right now — open or closed.
-
BrowseComp (75.9): This is a massive lead. GLM-5.1 is significantly better at navigating the web, extracting relevant information, and synthesizing findings than any competitor. If your agent needs to research and act, this matters.
-
MCP-Atlas (67.8): Tool usage through Model Context Protocol — GLM-5.1 connects to external tools more reliably than competitors. For developers building agent pipelines with MCP, this is the model to use.
-
NL2Repo: The ability to take a natural language description and generate an entire repository with correct structure, tests, and documentation. No other model has published competitive scores here yet.
Where it falls short:
- General reasoning (τ²-Bench): Claude Opus 4.6 and GPT-5.4 are still better at broad, non-coding reasoning tasks. If you need a general-purpose assistant, GLM-5.1 isn't the answer.
- Cost efficiency: The Vending Bench 2 scores show GLM-5.1 costs more per resolved issue than GPT-5.4, suggesting it sometimes takes more iterations to reach the same conclusion.
Coding Composite Score
When you combine the three core coding benchmarks (SWE-Bench Pro + Terminal-Bench 2.0 + NL2Repo), the coding composite leaderboard looks like this:
| Model | Coding Composite |
|---|---|
| GPT-5.4 | 58.0 |
| Claude Opus 4.6 | 57.5 |
| GLM-5.1 | 54.9 |
| Gemini 3.1 Pro | 52.0 |
| Qwen3.6-Plus | 52.0 |
| MiniMax M2.7 | 52.0 |
Interesting — on the composite, GLM-5.1 drops to third. This is because while it dominates SWE-Bench Pro specifically, Claude Opus 4.6 outperforms it on Terminal-Bench 2.0 (59.3 vs 56.2). The community consensus is that GLM-5.1 excels at investigation-heavy coding tasks where it can iterate and self-correct over time, while Claude remains more reliable for precision-first tasks where getting the answer right on the first attempt matters.
The 8-Hour Autonomous Demos: What Really Happened
The demos Z.ai published aren't typical "look at this cool prompt" showcases. They're genuinely unprecedented in scope:
Demo 1: Linux Desktop Environment from Scratch
GLM-5.1 was given a single instruction: "Build a complete Linux desktop environment." Over 8 continuous hours, the model:
- Planned the architecture for 50+ interconnected applications
- Wrote, compiled, and tested each component
- Identified bugs through self-review loops
- Refined the UI/UX based on its own analysis
- Added features autonomously that weren't in the original specification
- Iterated until convergence — stopping only when improvements plateaued
This is the kind of sustained, goal-directed behavior that earlier models simply couldn't maintain. Most LLMs lose coherence or start hallucinating after 30–60 minutes of complex agentic work. GLM-5.1's ability to maintain focus across 8 hours represents a genuine architectural advancement.
Several community members who attempted to replicate this described the model as working "like a senior engineer pulling an all-nighter" — occasionally making mistakes, but consistently catching and correcting them through systematic self-review.
Demo 2: Vector Database Optimization
Even more technically impressive in some ways: GLM-5.1 was tasked with optimizing a vector database. Over the course of the session, it:
- Executed 600+ sequential iterations
- Made 6,000+ individual tool calls
- Achieved a 6× performance improvement (from baseline to 21.5K QPS)
- Each iteration involved profiling, hypothesis generation, code modification, benchmarking, and analysis
This kind of systematic optimization work is exactly what agentic AI needs to do to be genuinely useful — not flashy one-shot answers, but methodical, patient engineering.
How to Run GLM-5.1: Complete Setup Guide
Option 1: Instant Access (Zero Setup)
If you just want to try GLM-5.1 immediately:
- Chat interface: Go to chat.z.ai — GLM-5.1 is available now
- API providers: Available through OpenRouter, Vercel AI Gateway, and Requesty
- Claude Code integration: GLM-5.1 works as a backend for Claude Code via API proxy
Option 2: Local Installation with GGUF (Private, Free)
This is where it gets interesting for the self-hosting crowd. Thanks to Unsloth's quantizations, you can run GLM-5.1 locally — albeit with significant hardware requirements.
Step 1: Install Prerequisites
example.sh1pip install -U huggingface_hubBASHUTF-8
Make sure you have llama.cpp compiled with Metal support (macOS) or CUDA (Linux/Windows):
example.sh1# macOS (Apple Silicon) 2git clone https://github.com/ggerganov/llama.cpp 3cd llama.cpp && make LLAMA_METAL=1 4 5# Linux (NVIDIA GPU) 6make LLAMA_CUDA=1BASHUTF-8
Step 2: Download the Quantized Model
For different hardware tiers:
example.sh1# For 32GB RAM (IQ2_M — smallest usable quant) 2huggingface-cli download unsloth/GLM-5.1-GGUF \ 3 --local-dir GLM-5.1-GGUF \ 4 --include "*IQ2_M*" 5 6# For 64GB RAM (IQ4_XS — better quality) 7huggingface-cli download unsloth/GLM-5.1-GGUF \ 8 --local-dir GLM-5.1-GGUF \ 9 --include "*IQ4_XS*" 10 11# For 128GB+ RAM (Q5_K_M — near-full quality) 12huggingface-cli download unsloth/GLM-5.1-GGUF \ 13 --local-dir GLM-5.1-GGUF \ 14 --include "*Q5_K_M*"BASHUTF-8
Step 3: Run Inference
example.sh1./llama-cli \ 2 --model GLM-5.1-GGUF/GLM-5.1-IQ2_M.gguf \ 3 --ctx-size 16384 \ 4 --n-gpu-layers 999 \ 5 --threads 8BASHUTF-8
Step 4 (Optional): Start an OpenAI-Compatible Server
If you want to use GLM-5.1 as a backend for OpenClaw, Claude Code, or other tools:
example.sh1./llama-server \ 2 --model GLM-5.1-GGUF/GLM-5.1-IQ2_M.gguf \ 3 --ctx-size 16384 \ 4 --n-gpu-layers 999 \ 5 --host 0.0.0.0 \ 6 --port 8080BASHUTF-8
Now any OpenAI-compatible tool can connect to http://localhost:8080/v1.
Option 3: Full-Scale Deployment (vLLM / SGLang)
For production or multi-user setups:
- Full BF16/FP8 weights: Available at huggingface.co/zai-org/GLM-5.1
- vLLM: Requires version 0.19+ with MoE support enabled
- SGLang: Requires version 0.5.10+ for GLM_MOE_DSA architecture
- Hardware: Minimum 4× A100 80GB or equivalent for full BF16
Hardware Requirements Reality Check
Let's be honest about what "running locally" actually means for a 754B-parameter model:
| Quantization | RAM Required | Speed | Quality | Realistic For |
|---|---|---|---|---|
| IQ2_M | ~32GB | Slow (~3–5 tok/s on M4 Max) | Usable but degraded | Experimentation only |
| IQ4_XS | ~64GB | Moderate (~8–12 tok/s) | Good | Serious local development |
| Q5_K_M | ~96–128GB | Good (~15+ tok/s) | Excellent | Production-grade local |
| Full BF16 | ~1.5TB VRAM | Fast | Perfect | Cloud/datacenter only |
The community is correct when they describe local GLM-5.1 as "painfully slow" on typical consumer hardware. This is a 754B model — even with efficient MoE routing, the sheer parameter count demands serious resources. The quantized versions are usable for development and testing, but if you need fast inference for production, the API route (chat.z.ai or OpenRouter) is the practical choice.
Pro Tip from the community: If you have a Mac Studio M4 Ultra with 192GB RAM, the IQ4_XS quantization runs surprisingly well. Several users on r/LocalLLaMA report using it as a daily driver for complex coding tasks, accepting the slower speed as a worthwhile tradeoff for complete privacy and zero API costs.
What the Community Actually Thinks
We combed through every relevant Reddit thread, Discord discussion, and forum post we could find. Here's the unfiltered community verdict:
The Praise
-
"Best open-source coding model, period": Multiple experienced developers confirmed that GLM-5.1 outperforms every other open-weight model they've tested for complex, multi-file engineering tasks. The self-review loops are particularly praised — it catches its own mistakes in ways that feel genuinely intelligent.
-
"Surprisingly competitive with Claude Opus": This is the recurring theme. Users who expected a significant gap between GLM-5.1 and top closed-source models are finding the difference is much smaller than anticipated, especially on investigation-heavy debugging tasks.
-
"The MIT license changes everything": For companies building products on top of AI, the MIT license (vs. Llama's custom license or GPT's API-only access) is a genuine differentiator. Multiple startups have already announced plans to build coding agent products on GLM-5.1.
The Criticism
-
"It's painfully slow locally": Valid, and expected at 754B parameters. Nobody should expect ChatGPT-like response times from local inference.
-
"Benchmark concerns": The "bench-maxxing" debate is real. Some community members argue that Z.ai may have specifically optimized for SWE-Bench Pro at the expense of broader capability. The coding composite score (54.9, trailing GPT-5.4's 58.0) lends some weight to this argument.
-
"Not great for general tasks": If you ask GLM-5.1 to write creative fiction, plan a vacation, or explain quantum physics, it works but feels clearly weaker than Claude or GPT. This is a coding specialist, not a generalist.
-
"Huawei training concerns": Some community members have raised political/supply-chain concerns about the model being trained on Huawei Ascend chips. Others counter that the MIT license and open weights mean the model's behavior is fully auditable regardless of training hardware.
GLM-5.1 vs. The Competition: Honest Recommendations
| Use Case | Best Model | Why |
|---|---|---|
| Autonomous coding agent (long sessions) | GLM-5.1 | Best sustained focus, self-review, 8+ hour capability |
| Precision-first coding (single-shot) | Claude Opus 4.6 | Higher first-attempt accuracy on Terminal-Bench |
| General-purpose professional work | GPT-5.4 | Strongest all-rounder with computer-use capabilities |
| Open-source coding on a budget | GLM-5.1 | MIT license, free local inference, no API costs |
| Web research + coding combined | GLM-5.1 | BrowseComp lead (75.9) is massive |
| Creative / non-coding tasks | Claude Opus 4.6 or GPT-5.4 | GLM-5.1 is a coding specialist |
Advantages and Disadvantages Summary
✅ Advantages
- #1 on SWE-Bench Pro — verified competitive advantage in autonomous coding
- MIT license — genuinely open, no restrictions on commercial use
- 8-hour autonomous sessions — unprecedented sustained agentic capability
- BrowseComp dominance — best web research integration of any model
- MCP-Atlas leader — most reliable tool usage for agent pipelines
- No NVIDIA dependency — trained on Ascend, available to everyone
❌ Disadvantages
- Massive hardware requirements — 754B parameters need serious resources even quantized
- Slow local inference — don't expect ChatGPT-speed responses on consumer hardware
- Coding specialist, not generalist — weaker on creative, conversational, and general reasoning tasks
- Benchmark skepticism — composite coding score (54.9) trails GPT-5.4 (58.0) and Claude (57.5)
- Early-stage ecosystem — fewer third-party integrations than established models
Resources and Links
- Official Blog: z.ai/blog/glm-5.1
- Full Weights: huggingface.co/zai-org/GLM-5.1
- GGUF Quantizations: huggingface.co/unsloth/GLM-5.1-GGUF
- Chat Interface: chat.z.ai
- Original Announcement: x.com/Zai_org/status/2041550153354519022
- Community: r/LocalLLaMA, r/ZaiGLM on Reddit
GLM-5.1 represents a genuine inflection point for open-source AI. For the first time, an open-weight model isn't just "competitive" with closed-source leaders on coding tasks — it's leading. The 8-hour autonomous sessions, the MIT license, and the BrowseComp dominance make it the obvious choice for developers building serious agent systems.
It's not perfect — the hardware requirements are steep, it's not a generalist, and the benchmark skeptics have valid points. But if you're building coding agents in 2026, you can't afford to ignore GLM-5.1.
Have you tried GLM-5.1? Share your hardware setup and experience in the comments. Did the 8-hour Linux desktop demo work for you? What quantization are you running? We're building a community benchmark database.
Last updated: April 9, 2026 — Benchmark data verified against Z.ai official publications, Artificial Analysis, and community reproductions.


